
1. 새로운 글 감지하기
1-1. 첫 번째 시도
1-2. 두 번째 시도
1-3. 세 번째 시도
1-4. 네 번째 시도
2. 속도 향상 & 사람인 척 하기
2-1. 도움이 되었던 글
2-2. 옵션 추가하기
2-3. 메서드
3. 에러 잡기
3-1. 첫 번째 에러
3-2. 두 번째 에러
1. 새로운 글 감지하기
1-1. 첫 번째 시도

학교 사이트에 들어가면 공지사항이 이렇게 나와있다.
셀레니움을 이용해서 이 페이지의 정보를 수집할 수 있다.
처음에는 게시물 번호를 이용해서 새로운 글이 올라왔는지를 판단해보려고 했다.
지금 가장 최근에 올라온 게시물번호가 '6811'인데
만약 내가 마지막에 확인한 게시물번호가 '6810'이었다면 새로운 게시물이 1개 올라왔다는 것을 알 수 있다.
이 방법을 이용하려고 했는데 종종 게시물번호가 이상하게 바뀌어버리는 문제가 발생했다.
심지어는 갑자기 게시물번호가 음수로 뜨는 경우도 있었다.
이렇게 정상적이지 않은 번호가 뜨는 경우 로직을 수행하지 않고
다시 처음부터 실행을 하도록 예외처리를 해서 문제를 해결했지만
근본적인 해결방법은 아닌 것 같았다.
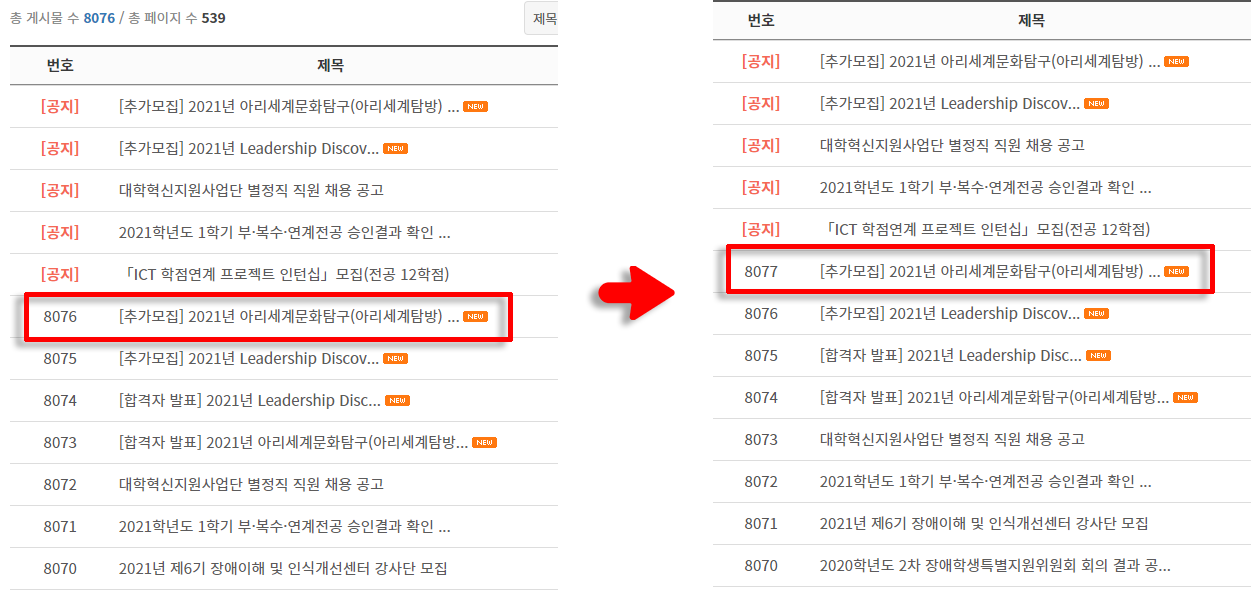
그러다가 기이한 현상(?)을 발견했다.
두 스크린샷은 같은 날에 찍은 건데 왼쪽이 오전에 오른쪽이 오후에 찍은 것이다.
갑자기 게시물번호가 1이 증가했다!!
새로운 글이 올라온 것이 아니다. 그냥 기존에 있던 게시물들이 전부 1씩 증가한 것이다.
나는 당연하게도 게시물 번호는 게시물마다 부여되는 고유의 번호이며
따라서 게시물을 구분할 수 있는 지표로 쓰일 수 있다고 생각했다...
이런 기이한 현상이 왜 일어나는지 너무 궁금해서
학교 웹사이트를 담당하시는 분을 찾아내서 여쭤봤다.
이런 거 여쭤보는 건 뭔가 실례..? 일 것 같아서 조심스레 여쭤봤는데 다행히도 답을 주셨다.
이유는 간단했다. 게시물들이 shift 되는 것이였다.
예를 들어, 이미 올라가 있는 중간에 위치한 글이 삭제됐을 때 번호가 하나 씩 당겨지는 것 말이다.
이걸 왜 생각 못했는지 모르겠다. 부끄러워서 도망치듯 끊었는데
번호가 늘어난 건 무슨 상황일까? 갑자기 중간 위치에 글을 추가하는 일도 생기는 걸까? 물어볼걸..
아무튼 게시물 번호를 사용하면 안 된다는 것을 알게 됐으니 다른 방법을 생각해내야 했다.
2. 두 번째 시도

그다음으로 사용할만한 방법이 이거였다.
url을 자세히 보면 여러 가지 정보를 알아낼 수 있는데
예를 들어 bsIdx는 카테고리를, page는 페이지 번호를 의미한다.
그리고 bIdx는 게시물을 가리키는 번호로 추측된다.
이전에 언급했던 게시물 번호는 외부로 보여지는.. 즉, 사용자에게 보여지는 번호고
이게 게시물을 가리키는 진짜 번호인 것 같다. 아마 board Index의 줄임말이 아닐까?
아무튼! 이걸 사용할까 했는데 역시 문제가 있었다.
이유는 모르겠지만 인덱스가 1씩 증가하는 것도 아니고
그렇다고 일정한 값만큼 증가하거나 규칙이 있지도 않았다.
112040 -> 112049 -> 112053...?
순서대로 올라온 게시물인데 번호가 지맘대로 증가한다.
사용을 하려면 할 수 있겠지만 불필요한 포문을 돌리고 싶지 않았고
bIdx값만 빼오고 하려면 과정이 길어지니까 좋은 방법이 아닌 것 같았다.
3. 세 번째 시도

어떤 방법을 사용해야 하나... 고민하다가 원시적으로 접근하기로 했다.
나는 이전에 없던 공지사항이 올라오면 "새로 올라온 글이구나"라고 인지를 한다.
그래서 최근 게시글 제목을 5개 정도 기억해뒀다가 비교하는 방법을 사용하기로 했다.
학교 공지사항 특성상 글이 연속으로 올라오는 일이 없어서 5개 정도면 적당할 것 같았다.

그래서 파이어 베이스에 1번 공지사항, 2번 공지사항... 5번 공지사항까지 저장을 해놓을까 했는데
이렇게 하면 매번 포문도 돌려야 하고...
새로운 공지 올라오면 가장 오래된 공지를 지우고 그 자리에 넣어야 하는데
shift 하면서 read/write를 더 많이 해야 해서 조금 변형을 시켰다.
따.. 딱히 read/write 횟수 많아지면 과금될 거 같아서 그런 건 아니고...
좀 더 효율적인 코드를 위해서 고민해봤다. 흠흠.

그래서 string 한 줄에 제목을 다 때려 넣었다.
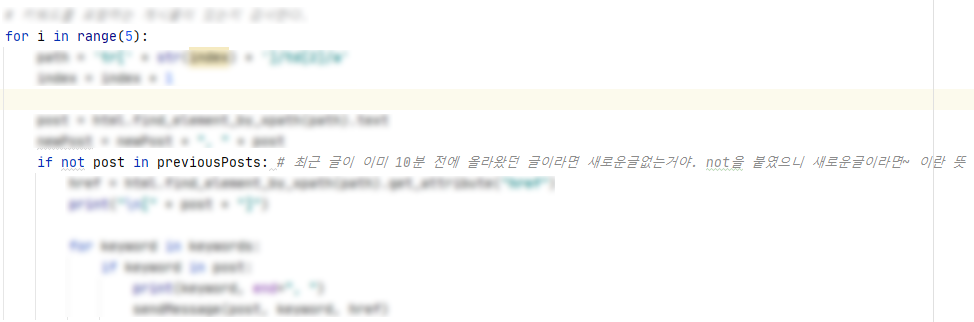
그리고는 문자열이 내가 찾고자 하는 제목을 포함하고 있는지 아닌지로
새로운 글의 여부를 확인하기로 했다.
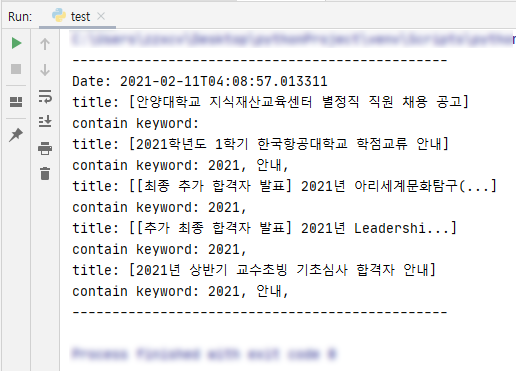
실행해봤더니 문제없이 잘 돌아간다.
만약 제목을 수정한다면 그 글을 새로운 글이라고 인식한다는 단점이 있지만
학교에서 나한테 API를 제공해줄 리도 없고 게시물 번호가 고정돼있는 값이 아니라서
이 방법이 최선일 거라는 결론을 내렸다.
4. 네 번째 시도 (2021.02.20 추가)
크롤링을 위해 사용했던 셀레니움이 너무 느리고 또 가끔씩 불완전한 모습을 보여줘서
웹 개발자 친구에게 자문을 구했다.
그리고 웹알못인 나에게 HTTP request라는 개쩌는 방법을 소개해줬다.
대체 난 여태까지 왜 셀레니움으로 쌩쇼를 했던 걸까?
학교 사이트를 분석해서 파라미터를 담은 POST 요청을 보내면 기가 막히게 빠른 속도로 공지사항 리스트를 가져올 수 있다.
bIdx값 또한 POST 요청으로 받을 수 있었고 이 값을 기준으로 새로운 글을 감지해봤더니
눈물 나게 잘된다. 이걸로 정착해야지 ㅠㅠㅠ 더 좋은 방법이 있을 줄이야..
때로는 삽질 열심히 파는 거보다 물어보는 게 더 현명하다는 걸.. 깨달았다.
2. 속도 향상 & 사람인 척 하기
2-1. 도움이 되었던 글
셀레니움은 실제로 브라우저를 띄워 페이지 정보를 수집하는 거다 보니 속도가 굉장히 느리다.
그리고 너무 잦은 요청을 시도할 경우 웹 사이트에서 이를 사람이 아니라고 감지하여 차단을 당할 수 있다! (두둥)
이를 해결하기 위한 방법을 이것저것 시도해봤는데 아래의 글이 굉장히 도움이 많이 되었다!
Selenium 으로 Web Scraping 아이 해봤니? | Popit
본 글은 테스트 자동화 도구로 잘 알려진 Selenium (셀레니움)을 이용하여 Java + Spring 환경에서 Web Scraping 을 구현해 본 경험에 대한 이야기 입니다.
www.popit.kr
나만의 웹 크롤러 만들기(7): 창없는 크롬으로 크롤링하기 - Beomi's Tech blog
2017-09-28 나만의 웹 크롤러 만들기(7): 창없는 크롬으로 크롤링하기 좀 더 보기 편한 깃북 버전의 나만의 웹 크롤러 만들기가 나왔습니다! 이번 가이드는 가이드 3편(Selenium으로 무적 크롤러 만들
beomi.github.io
2-2. 옵션 추가하기
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('window-size=1920x1080')
options.add_argument("disable-gpu")
options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36")
options.add_argument("lang=ko_KR")
options.binary_location = CHROME_LOCATION
chrome_options = options브라우저를 이용할 때 여러 가지 옵션을 줄 수 있다.
- headless: 인터넷 창을 띄우지 않고 크롤링을 할 수 있다. 불필요한 그래픽 자원 사용을 최소화시킨다.
- window-size=1920x1080: 창 크기를 설정해준다. 굳이 설정해주는 이유를 찾아보려 했는데 음.. 아마 화면의 크기나 비율에 따라 구성이 달라지는 웹사이트가 있기 때문 아닐까? (참고로 나는 웹 알못이다)
- disable-gpu: 크롬 브라우저를 사용할 때 생기는 문제점(버그)이 있는데 그걸 잡아준다.
- user-agent=Mozila...: 브라우저는 user-agent라는 값을 가지고 있는데, 이게 headless일 때는 값이 달라진다. 그래서 이 값을 통해 사람이 아닌지를 탐지해서 쫒아내버리는 경우가 있다고 한다. 그래서 임의로 정상적인 값을 넣어준 것이다.
- lang=ko_KR: 브라우저에는 사용자가 사용하는 언어가 무엇인지 저장되어있다. 근데 headless에는 없다. 그래서 로봇이 아닌 척하기 위해 언어를 임의로 추가해주는 것이다.
driver.execute_script("Object.defineProperty(navigator, 'plugins', {get: function() {return[1, 2, 3, 4, 5];},});")
driver.execute_script("Object.defineProperty(navigator, 'languages', {get: function() {return ['ko-KR', 'ko']}})")드라이버에도 몇 가지 옵션을 줄 수 있다.
- 브라우저(크롬)에는 확장 프로그램을 설치할 수 있다. 플러그인 이라고도 하는데 기본적으로 내장되어 있는 플러그인도 존재한다. headless에는 플러그인이 없으므로 이를 통해 로봇임을 감지할 수 있다고 한다. (하여튼 headless가 문제 구만?) 그래서 임의로 플러그인을 추가해주었다.
- 두 번째 실행문은 이전에 옵션에서 추가해주었던 언어를 등록하는 구문이다.
외에도 몇 가지 방법이 더 있는데
우리 학교 사이트는 로봇 감지를 빡빡하게 안 하는 것 같아서 이 정도만 해두었다.
더 다양한 방법은 2-1에서 언급한 블로거 분이 자세히 적어두셨다!
2-3. 메서드

셀레니움을 처음 사용해봤을 때 맨 위에 있는 메서드를 사용하면서
"아쒸 왜 element를 하나밖에 못 읽지?"라며 낑낑댔던 기억이 있다... ㅋㅋㅋ
element는 말 그대로 하나만 읽어오니 상황에 맞게 elements를 사용해야 요청 횟수를 줄일 수 있다.
너무 자주 요청하면 사이트에서 또 의심할 테니 :(
그리고 메서드의 속도는 xpath < CSS selector, Name selector < ID 순으로 빠르다고 한다.
xpath가 편해서 이걸로 썼는데 제기랄
def takeSomeRest():
rand_value = random.randint(1, 10)
sleep(rand_value)코드 실행 중간중간에는 랜덤한 시간만큼 잠시 쉬도록 해주었다.
셀레니움을 써보면 알겠지만 이건 뭐 거의 아이유 콘서트 티켓팅마냥 팎!팍!팍! 빠르게 진행되기 때문에
사람인 거처럼 하려면 중간중간 멈추는 게 필요하다고 생각했다.
3. 에러 잡기
3-1. 첫 번째 에러

크롤링 봇을 돌리다 보면 이따금 이런 에러가 뜨곤 한다.
페이지에서 요청한 Element를 찾을 수 없다는 뜻인데
경로를 잘못 지정했거나 등의 이유로 해당 위치에 Element가 없을 때 이 에러가 뜬다.
두 번째 에러에서 설명하겠지만 사이트 응답이 느린 경우가 가끔씩 있는데
아직 미처 페이지를 다 불러오지 못했는데 element를 가져오려다 보니 생기는 에러라고 추측하고 있다.
이 이유가 아니면 설명이 안된다!
왜냐면 안될 거면 아예 안돼야 하는데 한 20번 시도 중 1번은 이 에러가 뜬다.
어차피 10분마다 한 번씩 실행하도록 설정해두어서 try catch로 잡아서 해결하였다.
3-2. 두 번째 에러

또 문제 중에 하나가 TimedOutError가 뜨는 것이었다.
연결 요청 시간 초과인데 이건 셀레니움으로 접근할 때뿐만 아니라
그냥 평소에 학교 사이트를 이용할 때도 가끔씩 이런 에러가 뜬다.
다른 브라우저도 사용해봤지만 똑같다. 한 번 에러가 뜨면 1~2분 정도는 사이트에 접속이 안된다.
네이버나 구글 같은 건 잘 들어가지는데 학교 사이트만 그런 거 보니 사이트 문제이다.
try:
driver.implicitly_wait(10)
driver.get(SITE_URL)
html = driver.find_element_by_xpath('//*[@id="boardList"]/tbody')
except:
now = datetime.datetime.now()
print("TIMED_OUT_ERROR(Occurrence Time): " + now.isoformat())
sendMessage("Timeout error", "모니터링키워드", " ")
print("The error message sent to developer")
exit()driver.implicitly_wait() 메서드를 이용하면 지정한 시간만큼 페이지의 응답을 기다린다.
만약 응답이 너무 길어지면 그냥 프로그램을 종료해버리고
에러가 떴다는 사실을 내 핸드폰으로 푸시 알림을 보내게 해 두었다.
(문제가 생기면 로그를 확인해서 바로 조치해야 하니까..)
Python: 3.8
Pycharm: 2020.2.2 (Community Edition)
Selenium: 3.141.0
Chrome: 88.0.4324.150
Speech bubbles image CC by pngwing
https://www.pngwing.com/ko/free-png-nfnun
'앱 제작 > 키워드 알림 앱' 카테고리의 다른 글
| 1.1.0 패치 노트 (공지 추가, 연락처 검색 등) (0) | 2021.03.30 |
|---|---|
| 프로젝트 결과_최종_진짜진짜_마지막.txt (32) | 2021.02.28 |
| [학교 공지 알림 앱] 아냥이 프로젝트 최종 결과 (6) | 2021.02.06 |
| 파이어베이스 보안규칙 가입 없이 설정하기 (익명 로그인) (5) | 2021.02.01 |
| Inconsistency detected. Invalid view holder adapter positionMyNoticeViewHolder (부제: 스크롤을 너무 빠르게 내렸을 때 생기는 문제) (0) | 2021.01.27 |




댓글