
1. 문제
1-1. 링크
1-2. 문제 해석
2. 코드
3. 실행시간
1. 문제
1-1. 링크
SW Expert Academy
SW 프로그래밍 역량 강화에 도움이 되는 다양한 학습 컨텐츠를 확인하세요!
swexpertacademy.com
1-2. 문제 해석
부분 문자열을 사전 순으로 나열해 K번째에 위치하는 부분 문자열을 출력하는 문제다.
부끄럽게도 나는 문제를 잘못 해석해 삽질을 좀 했다.
우선 문제에서 말하는 부분 문자열에 대해 알아보자.
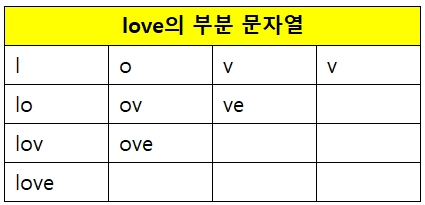
문제에서는 문자열의 두 위치를 골라서, 이 사이의 연속한 문자열을 부분 문자열이라고 정의하고 있다.
예를 들어 le는 연속된 문자열이 아니므로 부분 문자열이 아닌 것이다.
나는 모든 조합이 부분 문자열이 되는 줄 알고 조금 헤맸다.
근데 그것도 그거대로 말이 안 되는 게 문제에서 주어지는 문자열의 최대 길이가 400이라 미친듯한 경우의 수가 나온다.
아무튼 이게 부분 문자열!

부분 문자열을 구할때 고려할 점이 있다.
바로 중복을 제거해줘야 한다는 것이다.
food의 경우 'o'가 두 번 나와서 부분 문자열의 총개수는 9개가 된다.
즉, 주어지는 문자열의 길이로 부분 문자열의 개수를 확정지을 수 없다는 것을 염두에 둬야 한다.
- 풀이 방법 1
첫 번째 풀이 방법은 이중 포문을 돌며 모든 부분 문자열을 구하고.
Set에 저장해 중복을 제거한 뒤 정렬을 하고
다시 포문을 돌며 K번째 숫자를 찾는 방법이다.
'통과'에 의의가 있다면 이 방법도 충분히 가능하지만
좀 더 효율적인 방법을 배우고 싶다면 다음 방법을 사용하는 것이 좋다.
- 풀이 방법 2
접미사 배열(suffix array)과 LCP를 사용하는 방법이다.
복잡하지만 수학적인 방법으로 문제를 해결할 수 있어 꽤 효율적이다.
접미사 배열과 LCP에 대한 포스팅은 여기에서 확인할 수 있다.
이어지는 예제 설명은 위 포스팅을 이해하고 왔다는 가정하에 설명을 생략한다.

문자열 mommy가 주어졌다고 가정하자.
mommy로 접미사 배열과 LCP 배열을 만들면 위 표처럼 될 것이다.
이 문제에서는 Index가 필요 없으므로 Index는 머릿속에서 지워버려도 무방하다.
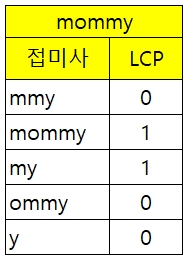
우리에게 필요한 건 위 표 하나만 있으면 된다.
이것만 있으면 K번째 부분 문자열이 무엇인지 구할 수 있다.
위 표에 있는 접미사들이 만들어 낼 수 있는 부분 문자열을 아래에 작성해 보았다.
- mmy
- m
- mm
- mmy
- mommy
- m
- mo
- mom
- momm
- mommy
- my
- m
- my
- ommy
- o
- om
- omm
- ommy
- y
- y
위 결과로 우리는 어떤 접미사가 만들 수 있는 부분 문자열의 개수는 접미사의 길이와 동일하다는 것을 알 수 있다.
mmy가 3개를 만들고 mommy가 5개를 만드는 것처럼 말이다.
즉, 우리는 모든 부분 문자열을 생성해보지 않아도 길이를 이용해서 K번째 부분 문자열을 빠르게 구할 수 있다는 것이다.
어? 근데 부분 문자열이 중복 생성되는 건 어떻게 처리하죠?
맞다. 위 부분 문자열 리스트를 다시 보면
mmy도 m을 생성했고
mommy도 m을 생성했고
my도 m을 생성하고 있다.
우리는 이 중복을 제거한 K번째 부분 문자열을 구해야 한다.
이때 필요한 것이 바로 LCP다.
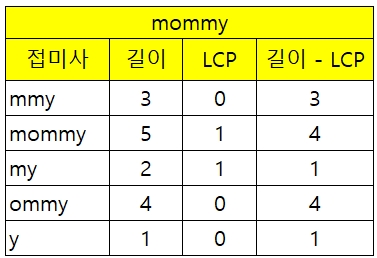
접미사의 길이 - LCP
(= 만들어낼 수 있는 부분 문자열의 개수 - 가장 긴 공통 접두사의 길이)
위 식으로 우리는 중복되지 않는 부분 문자열의 개수를 구할 수 있다.
맞는지 두 눈으로 확인해보자.
빨간 글씨는 중복된 부분 문자열을 표기한 것이다.
- mmy (3개)
- m
- mm
- mmy
- mommy (5개 - 1개)
- m
- mo
- mom
- momm
- mommy
- my (2개 - 1개)
- m
- my
- ommy (4개)
- o
- om
- omm
- ommy
- y (1개)
- y
이렇게 우리는 부분 문자열을 전부 다 만들지 않아도
접미사 배열과 LCP를 이용해서 K번째 수를 구할 수 있게 되었다.
예를 들어 K가 10이라고 하면
mmy가 3개니까 cnt = 3
mommy가 4개니까 cnt = 3 + 4 = 7
my가 1개니까 cnt = 3 + 4 + 1 = 8
ommy가 4개니까 cnt = 3 + 4 + 1 + 4 = 12
cnt가 K이상이므로 더 이상 찾기를 중단하고
ommy에서 0번째 인덱스부터 (cnt - K) 번째 인덱스까지 자르면
그게 바로 우리가 찾던 K번째 부분 문자열이 된다.
2. 코드
package algorithm;
import java.io.*;
import java.util.*;
public class Day13_1257_K번째_문자열 {
public static void main(String[] args) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
int testCase = Integer.parseInt(br.readLine());
for (int tc = 1; tc <= testCase; tc++) {
int K = Integer.parseInt(br.readLine());
String str = br.readLine();
String[] SA = new String[str.length()]; // suffix Array
int[] LCP = new int[str.length()];
// 접미사 저장 ex) love, ove, ve, e
for (int i = 0; i < str.length(); i++) {
SA[i] = str.substring(i, str.length());
}
// 사전순으로 정렬
Arrays.sort(SA);
// LCP 구하기
for (int i = 1; i < str.length(); i++) {
LCP[i] = getLCP(SA[i - 1], SA[i]);
}
// K번째 부분집합이 포함된 SA 인덱스 찾기
int cnt = 0;
for (int i = 0; i < str.length(); i++) {
cnt += SA[i].length() - LCP[i];
if (cnt >= K) {
String result = SA[i].substring(0, SA[i].length() - (cnt - K)); // **중요**
sb.append("#").append(tc).append(" ").append(result).append("\n");
break;
}
}
if (cnt < K) {
sb.append("#").append(tc).append(" ").append("none").append("\n");
}
}
bw.write(sb.toString());
bw.flush();
bw.close();
}
public static int getLCP(String s1, String s2) {
int len = Math.min(s1.length(), s2.length());
int cnt = 0;
for (int i = 0; i < len; i++) {
if (s1.charAt(i) != s2.charAt(i))
break;
cnt++;
}
return cnt;
}
}[목차 1-2]의 마지막 부분에서 cnt가 K를 넘어갈 때 멈추고 부분 문자열을 찾으라고 했는데
그 부분이 위 코드에서 **중요**라고 적은 부분이다.
3. 실행시간

만세 만세 만만세 ㅠㅠ
드디어 반에서 1등을 해봤다 ㅠㅠ (간발의 차이지만)
내 기록은 아직 싸피 전체 등수에 업데이트 되지 않았지만
273명 중에 4등 기록이다. 야호!
💡 느낀 점
- 진짜 이런 알고리즘 고안해낸 사람들은 다 천재면서
또라이인 것 같다. 와 이걸 어떻게... - 문제랑 알고리즘 둘 다 굉장히 흥미로웠고 신선했다.
- 맨버-마이어스 알고리즘도 사용하면 더 효율을 높일 수 있다는데 다음번엔 이것도 같이 적용해봐야겠다.
'문제 풀이 > SWEA' 카테고리의 다른 글
| 1259번 - 금속막대 (2) | 2021.09.05 |
|---|---|
| 1258번 - 행렬찾기 (0) | 2021.09.04 |
| 1221번 - GNS (0) | 2021.09.02 |
| 1248번 - 공통조상 (0) | 2021.09.01 |
| 1247번 - 최적 경로 (0) | 2021.08.31 |




댓글